豆包大模型是字节跳动研发的人工智能大模型,具备多轮对话、内容创作等核心能力,为用户提供智能、便捷的服务体验。
https://www.volcengine.com/product/doubao?from=doubao_product_page
- collect
- recommend
- Not recommended
product labeling
- LLM
- LLMs Service
For the crowd
- Creator
- Content operator
- Education practit...
- Self-Media

- Free Use
- Free Trial
- API
- Web Version
- plug-in
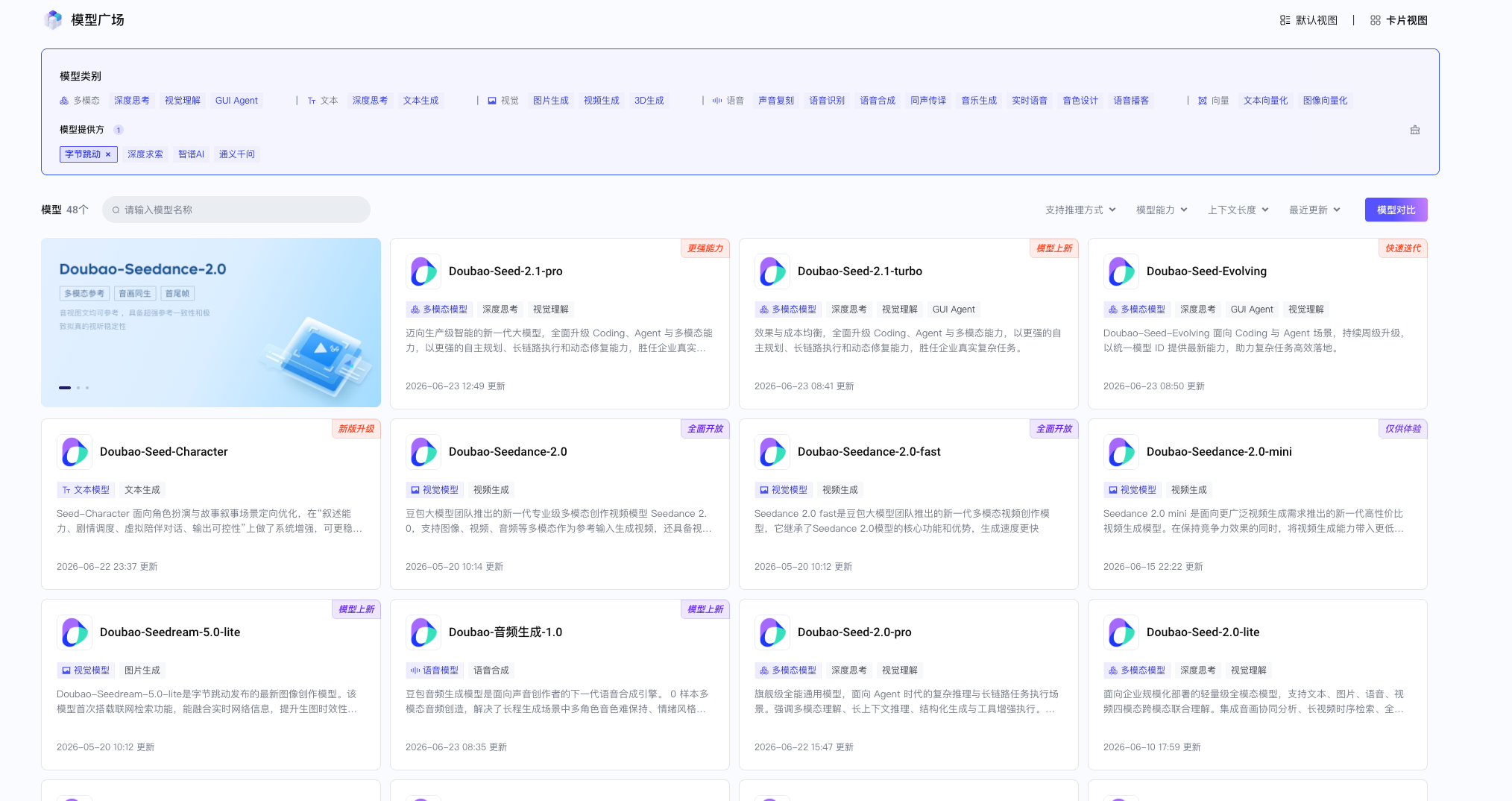
豆包大模型,Doubao家族模型,字节跳动推出的自研大模型。
拥有文本模型、视觉模型、语音模型、向量模型、多模态大模型等
语音大模型
Doubao-声音复刻; Doubao-语音合成; Doubao-同声传译; Doubao-流式语音识别; Doubao-录音文件识别; Doubao-实时语音交互; 音乐生成; 音色设计; 语音博客
视频生成
Doubao-Seedance-2.0; Doubao-Seedance-2.0-fast; Doubao-Seedance-2.0-mini; Doubao-Seedance-1.5pro; Doubao-Seedance-1.0pro; Doubao-Seedance-1.0pro-fast; Doubao-Seedance-1.0pro-lite-i2v; Doubao-Seedance-1.0pro-lite-t2v;
向量大模型
Doubao-embedding-vision;(图像向量化、文本向量化) Doubao-embedding-large; Doubao-embedding;
文本大模型
Doubao-Seed-Character; Doubao-Seed-Translation; Doubao-1.5-pro-32k; Doubao-1.5-lite-32k; Doubao-lite-32k;
图片生成
Doubao-Seedream-5.0-lite; Doubao-Seedream-4.5; Doubao-Seedream-4.0
多模态
Doubao-Seed-2.1-pro(深度思考/视觉理解); Doubao-Seed-2.1-turbo(深度思考/视觉理解/GUI Agent); Doubao-Seed-Evolving(深度思考/视觉理解/GUI Agent); Doubao-Seed-2.0-pro(深度思考/视觉理解); Doubao-Seed-2.0-lite(深度思考/视觉理解); Doubao-Seed-2.0-mini(深度思考/视觉理解); Doubao-Seed-2.0-code(深度思考/视觉理解); Doubao-Seed-1.8(深度思考/视觉理解); Doubao-Seed-1.6(深度思考/视觉理解); Doubao-Seed-1.6-lite(深度思考); Doubao-Seed-1.6-flash(深度思考); Doubao-Seed-Code(深度思考/视觉理解/GUI Agent)); Doubao-Seed-1.6-thinking(深度思考/视觉理解); Doubao-Seed-1.6-vision(深度思考);
3D生成
Doubao-Seed3D-2.0
1. 豆包大模型使用入口在哪里?
目前豆包大模型对接需通过字节自营平台“火山引擎”完成。
2.有哪些类型?
主推深度思考、视觉、视频生成3大场景
3.官方文档
https://www.volcengine.com/docs/82379
How do you feel about豆包大模型
Please log in before posting content


